
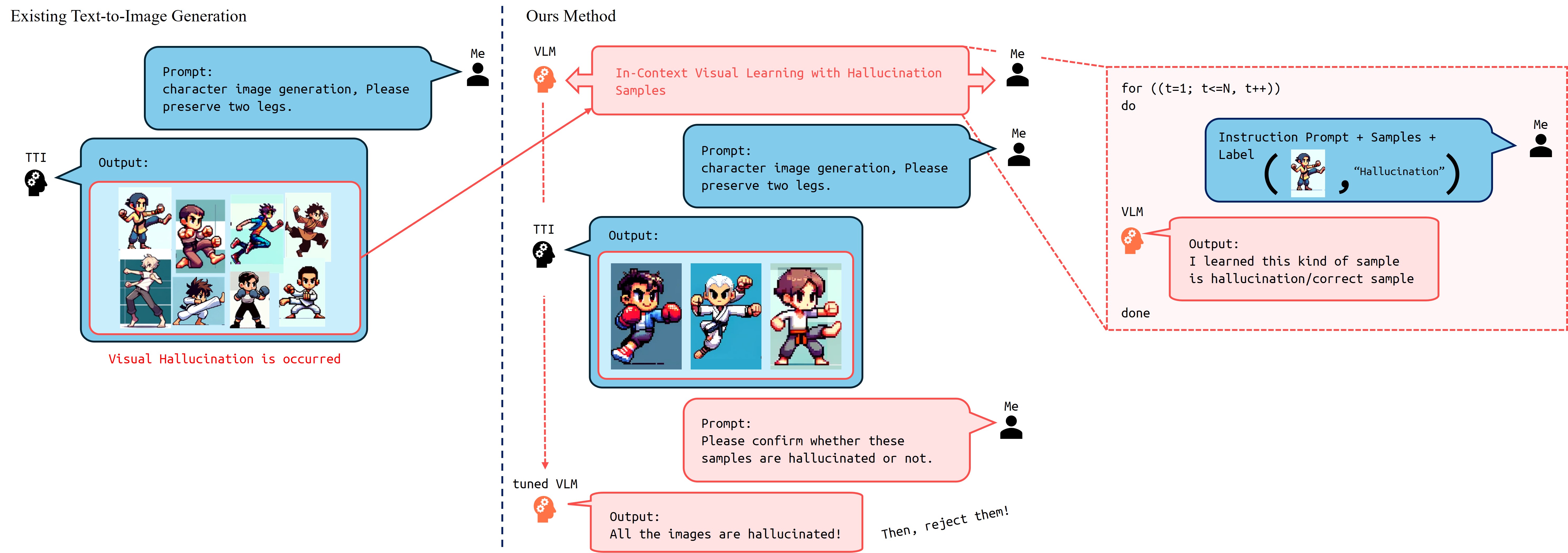
Large-scale Text-to-Image (TTI) models have become a common approach for generating training data in various generative fields. However, visual hallucinations, which contain perceptually critical defects, remain a concern, especially in non-photorealistic styles like cartoon characters. We propose a novel visual hallucination detection system for cartoon character images generated by TTI models. Our approach leverages pose-aware in-context visual learning (PA-ICVL) with Vision-Language Models (VLMs), utilizing both RGB images and pose information. By incorporating pose guidance from a fine-tuned pose estimator, we enable VLMs to make more accurate decisions. Experimental results demonstrate significant improvements in identifying visual hallucinations compared to baseline methods relying solely on RGB images. This research advances TTI models by mitigating visual hallucinations, expanding their potential in non-photorealistic domains.
@article{kim2024cartoon,
title={Cartoon Hallucinations Detection: Pose-aware In Context Visual Learning},
author={Kim, Bumsoo and Shin, Wonseop and Lee, Kyuchul and Seo, Sanghyun},
journal={arXiv preprint arXiv:2403.15048},
year={2024}
}